Отличначя статья http://www.robocraft.ru/my/Mirmik/ по созданию многозадачности для Arduino…. Читать ВСЕМ!!!! ![]()
Вытесняющая многозадачность для Arduino
1. Часть первая. Немного о многозадачности, ОС и контроллерах.
Вытесняющие операционные системы позволяют запускать на одном вычислительном ядре несколько не связанных между собой процессов. При этом, такие процессы, в отличие от кооперативных ОС, ничем не отличаются по стилю написания от своих однопоточных собратьев. Для микроконтроллеров такие операционные системы есть. Хотя бы та же FreeRTOS.
Операционная система – штука сложная. В центре ОС стоит диспетчер.
Диспетчер задач — это центральное звено ОС. Он рулит системой. Он раздаёт приоритеты процессам. Вызывает их в ему ведомом порядке. Дарует и отбирает управление. Диспетчер — это такой унылый программный бюрократ. Он выглядит важно и помыкает.
Но эти страшные штуки, приоритеты, планировка… Часто бывают избыточны для проектов на микроконтроллерах.
Вытесняющая многозадачность основывается на работе с контекстом процессов, на их сохранении и загрузке. В случае программирования для микроконтроллеров AVR (и, соответственно Arduino), эти вещи вполне обозримы и несложны для рядового пользователя. Это позволяет добавлять функции работы с контекстами процессов непосредственно в свои проекты.
Функции работы с контекстом – это как кирпичик. С помощью него можно построить дом «ОС»… Но им же можно и подпереть бочку.
Дом строить не будем. Бочку подопрём.
В рамках данной статьи я постараюсь доходчиво рассказать о нескольких внешне малосвязанных вещах.
Мы покричим на компилятор, шарахнемся от препроцессора, обманем среду Arduino, поймём инлайновость, помедитируем над Ассемблером, покиваем на соглашения языка Си, полазим в оперативке микроконтроллера и даже пнём опальный оператор goto… А под конец превратим ШИМ AVR в настоящий, хотя и простейший ЦАП (но это на сладкое, как лёгкий бонус)…
Что мы получим в результате? Написав пару простых функций на Ассемблере, и чуть-чуть сишного кода, мы получим пользовательскую библиотеку, позволяющую писать двухпоточные приложения. Или же одновременно с минимальными изменениями запускать два однопоточных приложения на одном контроллере. А так же рассмотрим пару примеров.
Почему ДВУХПОТОЧНУЮ? Потому что это наиболее просто. Понимая механизм работы простой библиотеки, не составит большого труда дополнить ее и создать на ее основе более сложную.
САМОЕ ГЛАВНОЕ — понимание того, что это не сложно. А это действительно так и дорогого стоит.
2. Часть вторая, подготовительная.
Установим немного конкретики.
Представленные ниже функции написаны под контроллер ATmega168 для среды разработки arduino-1.0.1. Никакими значимыми функциями среды Arduino при этом мы пользоваться не будем (до момента рассмотрения последнего примера), то есть, Arduino, вообще говоря, и не обязательна. Обычного WinAvr и ATmega168 вполне хватило бы.
Оформлять работу будем в виде пользовательской библиотеки. Для этого идем в \arduino-1.0.1\libraries и создаем там специальную папку. У меня это «\arduino-1.0.1\libraries\MirmPS» в эту папку положим потом несколько файлов. (подробнее о создании библиотеки смотри сюда).
Поставим задачу так: «Хочу, чтобы вместо одной циклической функции loop в скетче Ардуино можно было прописать loop1 и loop2, а также, чтобы контроллер выполнял их в режиме вытесняющей многозадачности. Для начала хотя бы по прерыванию от таймера».
3. Часть третья, микроконтроллерно-стековая.
Для того, чтобы понять изложенный здесь материал необходимо кое что знать.
Например, что такое контекст процесса.
Нужно немного представлять, внутреннюю архитектуру ядра AVR. Надо знать о существовании 32-х регистров общего назначения. Понимать, что регистр SREG важен, а также знать, что такое стек.
Так как основным нашим инструментом будет работа со стеком, я начну с того, что о нем напомню.
Стек это область оперативной памяти, в которую можно что-то положить, чтобы это что-то потом оттуда достать. Самая, на первый взгляд, значимая функция стека — сохранение точек входа подпрограмм (я буду называть их функциями). Когда программа вызывает функцию, контроллер сохраняет информацию о том, откуда сделан вызов. Выход из функции осуществляется путем извлечения этого «обратного адреса» и возвращения по нему. «Обратный адрес», он же «точка вызова подпрограммы», хранится в стеке в виде 16-ти битного числа (2 раза по байту). Если программа вызывает функцию, которая вызывает вторую функцию, в стек сначала попадает точка вызова первой, а затем второй функции. Обратный переход разрешается, как не трудно догадаться, в обратном порядке. Это называется LIFO (англ. last in — first out, «последним пришёл — первым вышел»).
То есть, фактически, стек – это вспомогательный массив в который постоянно записываются и из которого извлекаются адреса возвратов и другая информация, если ее необходимо ненадолго сохранить. Со стеком работает специальный 16-битный регистр, который называется указатель стека (Stack Pointer). Он показывает текущее место, в которое стек пишет и из которого читает. Если в стек пишут, указатель автоматически декрементируется. Читают — инкрементируется. При желании указатель стека можно программно переставить в другое место, чтобы обойти правило LIFO, или же вообще создать второй стек.
Отличительной особенностью стека (в контроллерах AVR) является то, что стек нарастает в порядке от старших адресов к младшим.
Теперь немного об оперативной памяти контроллера. Давайте посмотрим на картинку:
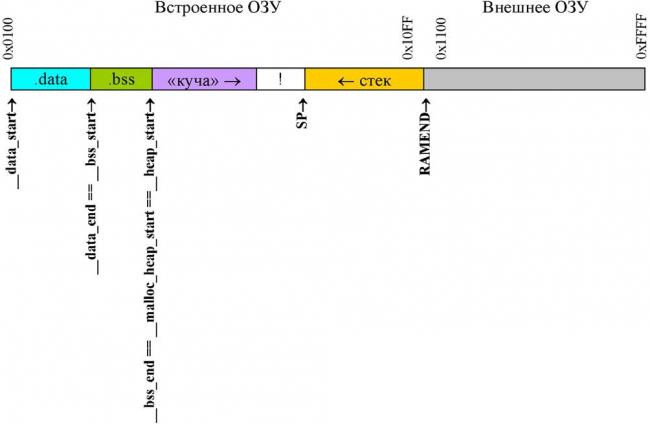
Картинка показывает нормальное распределение памяти для контроллера AVR. Внешнего ОЗУ у нас не будет. Области .data и .bss это то место, где компилятор велит хранить переменные. Обсуждение этих областей лежит вне тематики настоящего изложения.
Остаются «куча», «стек» и непонятный знак восклицания.
Куча — это пространство, в котором ничего нет. Предполагается, что эта часть используется для динамического распределения памяти, если таковое используется в программе, причем сначала распределяются младшие адреса. Пару слов об этом я еще скажу в самом к конце.
«Знак восклицания» — это небольшая уловка, чтобы стек не залез в кучу. Понимать его не обязательно, но отметить для себя надо следущее: динамическая память распределяется слева направо, а стек нарастает справо налево. Если они встретятся будет логический коллапс программы…
Итого картина такая:
Внешнего ОЗУ нет. .data и .bss — место где лежат переменные. Их трогать нельзя. На месте кучи и восклицательного знака пустое место. Его трогать можно. Справа стек. Стек растет налево. От старших адресов к младшим.
Пойдем дальше. Контекст процесса — это информация, о точке текущей выполнения процесса, а так же информация о состоянии контроллера, которая необходима, чтобы процесс выполнялся правильно. Если мы сохраним контекст, а потом через какое-то время загрузим его назад, то программа, как ни в чем не бывало, продолжит работу с того места, на котором прервалась. Собственно, это и есть наилучшее определение контекста. То, что надо сохранить для корректного возобновления процесса – контекст процесса.
Как вы знаете программа для процессора – это список инструкций. Это как длинный свиток, на котором языком доступным процессору по пунктам объясняется чего ему делать. Процессор выполняет инструкцию и переходит, либо к следующей инструкции, либо к какой-то иной, если так велено предыдущей инструкцией. Каждая строчка в этом свитке пронумерована. Номер той строчки которую процессор выполняет прямо сейчас храниться в Programm Counter и называется, допустим, адресом текущей инструкции.
Логично предположить, что при остановке процесса и передаче управления другому процессу, самое главное сохранить именно адрес текущей инструкции (состояние Programm Counter), но одного этого недостаточно. Также необходимы 32 регистра общего назначения, регистр SREG, указатель стека (Stack Pointer) и сам стек, ибо они несут в себе информацию, которую процесс уже обработал, или же, с которой он работал прямо на момент останова. Без этих элементов программа логически развалиться (может и не развалиться, если очень повезет). При желании можно добавить к контексту что-нибудь еще, например состояние периферии или каких-либо переменных, если это необходимо.
SREG — статусный регистр. Достаточно знать, что он важен для правильного выполнения условных операторов и операторов цикла. Также там храниться флаг глобального разрешения прерываний.
Так как же сохранить процесс?
Вообще-то тут есть варианты.
Мы сохраним контекст процесса путем запихивания его в стек и сохранения того адреса, по которому из стека контекст потом можно будет извлечь (указателя стека). Указатель стека будем хранить как обычную переменную. Соответственно в той самой области, которая .data и .bss…
Но это то, что касается одного процесса. Для второго процесса мы искусственно сделаем второй стек. Что-бы не очень углубляться в адресную математику, для простоты, закинем его в середину пустой области памяти. В кучу.
И будет у нас два стека. По стеку под каждый процесс.
4. Часть четвертая, в которой мы дорвёмся до ассемблера и напишем немного макросов.
Ассемблер — очень простой язык. Потому что без выпендрежа. Но писать на нем сложно. Потому что все надо расписывать подробно.
Вам несомненно известно, что человек умеет брать кружку.
Потянуться к кружке. Взять. Это Си.
Когда и какую мышцу напрячь, сгибать ли пальцы, куда смотреть, как определить, что рука приблизилась к кружке… И конечно, не забывать дышать. Это ассемблер.
Он подробный. Но простой.
Для затравки напишем простую функцию, которая будет для нас сохранять часть контекста (32 регистра общего назначения и регистр SREG).
(За подробностями по ассемблеру языка AVR я отсылаю вас к замечательной книжке: «Микроконтроллеры AVR практикум для начинающих», автор В.Я.Хартов)
Вот код. Он не для программы. Он для анализа:
push r0 ; push r0 – директива, командующая положить в стек
; содержимое регистра r0.
in r0, SREG ; Теперь запишем в регистр r0 состояние регистра SREG
push r0 ; и сохраним его.
push r1 ; Сохраняем содержимое r1
clr r1 ; Очищаем регистр r1
push r2 ;
push r3 ;
push r4 ;
push r5 ;
push r6 ;
push r7 ;
push r8 ;
push r9 ; И
push r10 ; по
push r11 ; очереди
push r12 ; сохраняем
push r13 ; все
push r14 ; регистры
push r15 ;
push r16 ;
push r17 ;
push r18
push r19
push r20
push r21
push r22
push r23
push r24
push r25
push r26
push r27
push r28
push r29
push r30
push r31 ; всё…
(Примечание: очищение регистра r1 – это дань соглашениям языка Си, по которым r1 всегда должен содержать константу 0×00. Почистить его не вредно, хотя в рамках нашей библиотеки — избыточно.)
Просто?.. Думаю да.
Теперь этот код надо как-то встроить в нашу программу. (Да, программы еще нет, но продумать этот момент можно уже сейчас).
В языке Си предусмотрено два основных способа работы с подпрограммами. Если коротко, инлайнить и не инлайнить. Разниться такова. Инлайновая функция — это не подпрограмма. Это просто кусок кода, который компилятор подставит вместо вызова подпрограммы. Неинлайновая функция — это подпрограмма. Встретив вызов, программа передает управление подпрограмме, и в дальнейшем управление передается назад на точку вызова по адресу сохраненному в стеке. При программировании на языке высокого уровня разница в скорости выполнения и занимаемой памяти… То есть, в общем, никакой…
А вот для нас разница есть. Адрес точки возвращения. Дело в том, что положив адрес в стек при вызове подпрограммы, мы будем потом вынуждены его считать, чтобы вернуться. А над ним сохранены состояния 32 регистров общего назначения, да SREG затесался (помните про LIFO?). Обойти их, конечно можно, но зачем?.. Будем инлайнить.
В Си инлайновые ассемблерные функции принято описывать в виде макроса, ссылающегося на ассемблерную вставку. (О макросах читайте в интернете, а про ассемлерную вставку можно сюда сюда)
Выглядит это так (прошу заметить, что это уже не ассемблер. Это Си… ):
#define saveContext() \ //#define saveContext() – объявление макроса
asm volatile ( "\n\t" \ //asm – расширение, указывающее на
"push r0 \n\t" \ //ассемблерную вставку. volatile – просьба к
"in r0, __SREG__ \n\t" \ // компилятору не зазнаваться и руками не
"push r0 \n\t" \ //трогать. Это на всякий случай.
"push r1 \n\t" \
"clr r1 \n\t" \
"push r2 \n\t" \
"push r3 \n\t" \
"push r4 \n\t" \ // "push r4 \n\t" \ - ассемблерный листинг
"push r5 \n\t" \ // передается как строка. кавычки ограничивают
"push r6 \n\t" \ // \n\t – указывает на переход строки внутри
"push r7 \n\t" \ // команды asm.
"push r8 \n\t" \ // внешняя косая черта – относится к макросу.
"push r9 \n\t" \ // Это своеобразная конкатенация.
"push r10 \n\t" \
"push r11 \n\t" \
"push r12 \n\t" \
"push r13 \n\t" \
"push r14 \n\t" \
"push r15 \n\t" \
"push r16 \n\t" \
"push r17 \n\t" \
"push r18 \n\t" \
"push r19 \n\t"\
"push r20 \n\t" \
"push r21 \n\t" \
"push r22 \n\t" \
"push r23 \n\t"\
"push r24 \n\t" \
"push r25 \n\t" \
"push r26 \n\t" \
"push r27 \n\t" \
"push r28 \n\t" \
"push r29 \n\t"\ // всё…
"push r30 \n\t" \
"push r31 \n\t");Итак, лёд тронулся. У нас есть первый макрос. Он рабочий. Конечная программа будет его использовать. Давайте в догонку сразу же рассмотрим и обратную функцию, загружающую ранее сохраненные 32 регистра и SREG:
И здесь всё тоже самое, только в обратном порядке…
#define loadContext() \
asm volatile ("\n\t" \
"pop r31 \n\t" \
"pop r30 \n\t" \
"pop r29 \n\t" \
"pop r28 \n\t" \
"pop r27 \n\t" \
"pop r26 \n\t" \
"pop r25 \n\t" \
"pop r24 \n\t"\
"pop r23 \n\t" \ // директива pop – это извлечение из стека
"pop r22 \n\t" \
"pop r21 \n\t" \
"pop r20 \n\t" \
"pop r19 \n\t" \
"pop r18 \n\t" \
"pop r17 \n\t" \
"pop r16 \n\t" \
"pop r15 \n\t" \
"pop r14 \n\t"\
"pop r13 \n\t" \
"pop r12 \n\t" \
"pop r11 \n\t" \
"pop r10 \n\t" \
"pop r9 \n\t" \
"pop r8 \n\t" \
"pop r7 \n\t" \
"pop r6 \n\t" \
"pop r5 \n\t" \
"pop r4 \n\t"\
"pop r3 \n\t" \
"pop r2 \n\t" \
"pop r1 \n\t" \
"pop r0 \n\t" \
"out __SREG__, r0 \n\t" \
"pop r0 \n\t");Тут уже всё знакомо.
Теперь давайте создадим в нашей библиотеке файл «.h» у меня это «MirmPS.h» и добавим туда 2 готовых макроса.
Итого, мы сохранили регистры общего назначения и статусный регистр. По плану еще Programm Counter, Stack Pointer, и сам стек.
Стек сохранять не будем. Действительно, а как его сохранять, если сохраняем мы в нем. Его сохранность гарантируется тем, что его не трогают, пока не позволено. Сохранение Programm Counter — это отдельная тема. Об этом позже.
Stack Pointer — это просто. Указатель стека состоит из двух регистров. SPH и SPL. Надо создать переменные, в которых мы будем их хранить для каждого процесса. И немного макросов для работы с ними. Еще немного кода:
typedef volatile union Spt //Определяем тип для хранения
{int i; //StackPointer; Определение
char c[2]; //на основе union позволит
} SPstore_t; //обращаться со значением
//и как с int и как с char[2]
extern SPstore_t SPstore[2]; //Определение массива на два указателя
//прямая установка StackPointer.
#define setStackPointer(x,y) {SPH=x;SPL=y;}
//макросы для работы с SPstore. Запись и Чтение.
#define copyStackPointer(x) {x.c[1]=SPH;x.c[0]=SPL;}
#define loadStackPointer(x) {SPH=x.c[1];SPL=x.c[0];} Что такое union можно почитать в интернете.
copyStackPointer и loadStackPointer работают на тип SPstore_t. Такая странная декларация типа нужна, чтобы было проще извлекать SPL и SPH по отдельности, но в то же время иметь возможность работы с полным указателем стека.
volatile — это просьба компилятору не трогать ничего без надобности, а extern — указание на то, что SPstore[2] будет использоваться в каком-то другом файле.
Теперь полный код MirmPS.h:
#include "MirmPS_assemf.h"
#ifndef Mirm_PS_h //Защита от двойного подключения
#define Mirm_PS_h
typedef volatile union Spt //Определяем тип для хранения
{int i; //StackPointer; Определение
char c[2]; //на основе union позволит
} SPstore_t; //обращаться со значением
//и как с int и как с char[2]
extern SPstore_t SPstore[2]; //Определение массива на два указателя
//прямая установка StackPointer.
#define setStackPointer(x,y) {SPH=x;SPL=y;}
//макросы для работы с SPstore. Запись и Чтение.
#define copyStackPointer(x) {x.c[1]=SPH;x.c[0]=SPL;}
#define loadStackPointer(x) {SPH=x.c[1];SPL=x.c[0];}
#define saveContext() \ // Макрос сохранения контекста.
asm volatile ( "\n\t" \
"push r0 \n\t" \
"in r0, __SREG__ \n\t" \
"push r0 \n\t" \
"push r1 \n\t" \
"clr r1 \n\t" \
"push r2 \n\t" \
"push r3 \n\t" \
"push r4 \n\t" \
"push r5 \n\t" \
"push r6 \n\t" \
"push r7 \n\t" \
"push r8 \n\t" \
"push r9 \n\t" \
"push r10 \n\t" \
"push r11 \n\t" \
"push r12 \n\t" \
"push r13 \n\t" \
"push r14 \n\t" \
"push r15 \n\t" \
"push r16 \n\t" \
"push r17 \n\t" \
"push r18 \n\t" \
"push r19 \n\t"\
"push r20 \n\t" \
"push r21 \n\t" \
"push r22 \n\t" \
"push r23 \n\t"\
"push r24 \n\t" \
"push r25 \n\t" \
"push r26 \n\t" \
"push r27 \n\t" \
"push r28 \n\t" \
"push r29 \n\t"\
"push r30 \n\t" \
"push r31 \n\t");
#define loadContext() \ // Макрос загрузки контекста.
asm volatile ("\n\t" \
"pop r31 \n\t" \
"pop r30 \n\t" \
"pop r29 \n\t" \
"pop r28 \n\t" \
"pop r27 \n\t" \
"pop r26 \n\t" \
"pop r25 \n\t" \
"pop r24 \n\t"\
"pop r23 \n\t" \
"pop r22 \n\t" \
"pop r21 \n\t" \
"pop r20 \n\t" \
"pop r19 \n\t" \
"pop r18 \n\t" \
"pop r17 \n\t" \
"pop r16 \n\t" \
"pop r15 \n\t" \
"pop r14 \n\t"\
"pop r13 \n\t" \
"pop r12 \n\t" \
"pop r11 \n\t" \
"pop r10 \n\t" \
"pop r9 \n\t" \
"pop r8 \n\t" \
"pop r7 \n\t" \
"pop r6 \n\t" \
"pop r5 \n\t" \
"pop r4 \n\t"\
"pop r3 \n\t" \
"pop r2 \n\t" \
"pop r1 \n\t" \
"pop r0 \n\t" \
"out __SREG__, r0 \n\t" \
"pop r0 \n\t");
#endif#include «MirmPS_assemf.h» — Это для того чтобы подключить еще одну ассемблерную функцию. Она будет уже настоящей, не инлайновой. Но это чуть позже.
MirmPS.h можно заворачивать и не трогать.
5.Часть пятая, в которой мы переписываем main функцию.
Я думаю, для вас не секрет, что скетч, который пишется для создания проекта на Arduino, не что иное как полуфабрикат, который перед линкованием вставляется в main.cpp, лежащий в папочке cores. И именно main.cpp, а не скетч, по сути, является основной программой.
И мы его перепишем. Но сделаем это аккуратно. Разработчики Arduino толи специально, то ли по недосмотру дали пользователю возможность переписывать системные функции без изменения библиотек ядра.
Дело в том, что при линковании и компиляции все функции, лежащие в папке hardware/arduino/cores собираются и архивируются в статическую библиотеку core.a (подробности смотри в логах компиляции), а пользовательские библиотеки не архивируются.
Если не вдаваться в подробности, то у статической библиотеки низкий приоритет относительно не архивированных файлов.
Это даёт нам возможность скопировать main.cpp из hardware/arduino/cores в папку нашей пользовательской библиотеки. Отныне функция main будет читаться отсюда. Здесь мы ее и перепишем.
Примечание: Что очень полезно, это верно только в случае, если в скетче будет подключена пользовательская библиотека, содержащая замененную функцию. Таким образом для отключения функции и возвращения к ядровому варианту будет достаточно не подключать соответствующую пользовательскую библиотеку. Это даёт пользователю богатые возможности по гибкому модифицированию ядра Arduino.
Итак, копируем main.cpp из hardware/arduino/cores в папку нашей пользовательской библиотеки.
Пусть основная часть кода в функции main выглядит так:
void loop1(void);
void loop2(void); //Функции реализованы в скетче.
void setup(void);
int main(void) //Точка входа программы.
{
init(); //Настройка ядра Ардуино. В основном таймеры.
cli(); //init() разрешает прерывания. но
//нам они пока не нужны. Запретим.
branching();//Ветвитель потоков.
return 0; //Сюда программа не попадёт.
}
volatile void programm1(void){ //А это два наших потока.
setup(); sei(); //Первый поток вызывает также cодержит
for (;;) {loop1(); //функцию setup.И разрешает прерывания.
}
} //За их вызов ответственна
volatile void programm2 (void){
for (;;) {loop2();} //функция branching()
}
Таким образом:
Порядок действий такой. Инициализация ядра Arduino. Отключение прерываний, которые функция инициализации слишком рано включает и тут же вызов функции branching().
Что это такое? Это ветвитель. Коротенькая подпрограмма, который превращает один поток в два. Для этого ветвитель сохраняет исходный поток и копирует сохраненный поток на новое место, запоминая новый адрес. Теперь потоков будет два и они одинаковые. Далее он передает управление первому потоку. Ветвитель устроен таким образом, что первый и второй потоки, будучи одинаковыми на момент создания, имеют разные точки выхода из функции. Точка выхода первого потока из ветвителя — функция programm1. Второго — programm2.
6. Часть шестая, заумная, в которой мы понимаем работу ветвителя.
На практике всё немного сложнее, чем в теории. Системой команд AVR не предусмотрено директив, позволяющих напрямую скопировать содержимое счетчика команд (Programm Counter). А нам нужно его скопировать, да еще таким образом, чтобы потом можно было загрузить. Проблема эта обходится.
Мы сделаем это, подсунув программе специальную функцию, при входе в которую содержимое счётчика автоматически копируется в стек. Тут то мы его и возьмём.
Наверное, ветвитель — это самая главная и из-за проблем с доступом к авровскому счетчику команд — самая не очевидная функция в этой библиотеке. Его работу я постараюсь разобрать подробно.
Код:
volatile SPstore_t SPstore[2]; // Здесь храняться указатели стека
// сохраненных потоков.
volatile int Taskcount=0; // Это счетчик выходов из ветвителя.
void branching(void)__attribute__((always_inline));
void branching_2 (void)__attribute__((naked,noinline));
void branching(void)
{ setStackPointer(0x04,0xFF); // установка SP в RAMEND
branching_2(); // точка вызова процедуры
// копирования.
//В эту точку возвращаются новые потоки.
//векторы выхода потоков из ветвителя:
if (Taskcount==0) {Taskcount++;goto *programm1;}
if (Taskcount==1) {Taskcount++;goto *programm2;}
}
void branching_2 (void)
{ saveContext(); //Сохраняем
SPstore[1].i=copyContext(0x040A); //Копируем
loadContext(); //Загружаем
//т.к. функция naked, нужно явно объявить возврат
asm("ret"); //Возвращаемся.
}
Начнем с простого. volatile SPstore_t SPstore[2]; — это старый знакомый. Он был определен в файле MirmPS.h. В него мы будем писать сохраненные указатели стека.
volatile int Taskcount=0; — это переменная на основе значения которой будет произведена процедура ветвления.
Далее сразу же бросается в глаза нестандартная декларация функций
void branching(void)__attribute__((always_inline));
void branching_2 (void)__attribute__((naked,noinline));Компилятор GCC, используемый средами Arduino и WinAVR понимает специальное ключевое слово __attribute__, которое используется для подсоединения различных атрибутов к функциям, определениям, переменным и типам. Это ключевое слово сопровождается спецификацией атрибута в двойных круглых скобках. Аттрибуты — это указания компилятору на то, как именно следует обработать данную функцию тип или переменную.
Перечень аттрибутов можно посмотреть здесь
Начнем со второй функции __attribute__((naked,noinline)).
__attribute__((naked)) это запрет компилятору оформлять точку вызова функции операциями сохранения регистров. По умолчанию, вызов функции оформляется сохранением некоторого контекста. Какого. Нужного. Компилятор знает какого… Я не знаю… А мне надо работать со стеком и я не хочу, чтобы в стеке был мусор… Поэтому то и naked. __attribute__((noinline)) запрещает компилятору делать функцию инлайновой. Зачем оно надо, я только что рассказал, ведь branching_2 — это та подставная функция, что позволит распотрошить счетчик команд.
Теперь первая функция.
Аттрибут always_inline приказывает компилятору встроить функцию вместо ее вызова. Если модификатор inline — это скорее просьба то always_inline — это приказ.
Есть, правда, одно но. Компилятор выполнит его только в случае, если сможет. Для того, что он смог, сама функция и ее вызов должны быть описаны в одном файле.
На самом деле, если использование __attribute__((naked,noinline)) для branching_2 — это все-таки необходимость, то использование always_inline для branching — это блажь.
Посмотрите внимательно на код. Первым же оператором
setStackPointer(0x04,0xFF)Я даже больше скажу. Вы думаете, что СИ, передавая управления в функцию main делает это с пустым стеком?.. ЧУШЬ!..
В стеке на момент вызова функции main содержится… Никогда не догадаетесь, но это точка вызова функции main. Main, кстати определена с типом int по стандарту gcc. Кому функция main, живя на микроконтроллере, собирается возвращать значение — тайна великая. Эта глупость — следствие кросплатформенности компилятора. Тяжелое наследство его писишных товарищей…
(Примечание: Если конечно у вас нету полноценной операционки и файловой системы…)
Однако вернемся к нашему ветвителю.
void branching(void) //inline
{ setStackPointer(0x04,0xFF);
branching_2();
//В эту точку возвращаются новые потоки.
if (Taskcount==0) {Taskcount++;goto *programm1;}
if (Taskcount==1) {Taskcount++;goto *programm2;}
}
void branching_2 (void) //naked, noinlie
{ saveContext();
SPstore[1].i=copyContext(0x040A);
loadContext();
asm("ret");
}Следущая строчка SPstore[1].i=copyContext(0x040A); оперирует функцией, которая пока еще не написана. Эта функция берет 35 сохраненных байтов из стека и копирует их в другую область памяти. Значение 0x040A выбрано почти наобум. Это место далеко и от стека и от данных. Это середина кучи. Функция copyContext(0x040A), кроме прочего возвращает адрес в который надо установить указатель стека, чтобы второй стек можно было корректно считать.
И, да! Теперь у нас есть два стека в разных частях памяти. И есть проблема. Они одинаковые.
Поэтому, загрузив назад контекст первого процесса loadContext()
внимание: функция copyContext(0x040A) указатель стека не перемещает. Где он был на момент копирования, там он и остался.
——–, мы говорим:
asm("ret");Это ассемблерный вызов, который вернет нас по сохраненному при входе в branching_2()адресу.
Вызовется точка возврата и так как Taskcount равен 0, сработает строка
if (Taskcount==0) {Taskcount++;goto *programm1;}Итак, мы вышли из ветвителя к первой программе. Сложно? Вроде не очень. Чего же я тут так подробно распинаюсь?
Дело все в том что работа функции branching() еще не закончена, ибо второй поток все еще в ней!!!
И чтобы понять, как второй поток будет из нее выбираться, посмотрим на вызов переключения контекста. В нашем же случае сигнал на переключение контекста дает таймер2.
Код выглядит так.
ISR(TIMER2_OVF_vect,ISR_NAKED)
{
saveContext(); // Сохраняем контекст.
if ((SPH*0x100+SPL)<0x420) // Очень глупый способ
// вычисления активного потока.
{
copyStackPointer(SPstore[1]);
loadStackPointer(SPstore[0]);
} // Сохраняем один SP
else
{ // И загружаем другой.
copyStackPointer(SPstore[0]);
loadStackPointer(SPstore[1]);
}
loadContext(); //Загружаем новый контекст.
asm("reti"); //Возврат из прерывания.
}Функция обработчика прерывания топорная, как топор, и на диспетчер задач ни разу не тянет. Ее единственная цель демонстрация возможностей построения многозадачных приложений.
ISR(TIMER2_OVF_vect,ISR_NAKED).ISR — это объявление обработчика прерывания.
TIMER2_OVF_vect — конкретизирует, мол что прерывание это при переполнении таймера 2.
(Таймер 2 уже включен в функции init(). Разрешение прерывания будет установленно в функции setup() при начале работы первого процесса.)
ISR_NAKED — это naked. Это разговор с компилятором, мол, не сохранять регистры, и руками не трогать…
Код особо комментариев не требует. Сохраняем контекст.
Если ((SPH*0×100+SPL)<0×420), тоесть процесс 2, то меняем шило на мыло, если нет то мыло на шило, путем сохранения текущего указатели стека одного процесса и загрузки указателя стека другого процесса. Наконец, загружаем контекст из стека. Поздравляю, мы в другом потоке и видим ассемблерный вызов asm(«reti»);.
Если вы посмотрите в справочник по системе команд AVR, то увидите, что это выход из прерывания. Выход, разумеется, в по тому адресу возврата, на который смотрит Stack Pointer в момент выполнения директивы. Фокус в том, что директиве reti без разницы, по чьему адресу выполнять возврат. Оставлен он родным прерыванием или же левой функцией, для неё разницы нет.
А Stack Pointer нашего второго потока, при его первом вызове, после загрузки контекста смотрит аккурат не куда-нибудь а на адрес, возврата из функции branching_2().
То есть в точку, которую я пометил как «//В эту точку возвращаются новые потоки.»
Ну, а чего? Копия же.
Так и срабатывает ветвление, ибо Taskcount со времен прошлого прохода равно 1.
Работает строка
if (Taskcount==1) {Taskcount++;goto *programm2;}Вот таким вот образом. Разумеется, такой способ создания нового потока не единственно возможный, но, ИМХО, весьма простой.
Смена контекста теперь происходит при каждом прерывании счетчика Timer2. Удовольствие, кстати сказать, не дешевое. Обработчик прерываний съедает на себя около 140-160 тактов… (команды push и pop выполняются в 2 такта) В рамках работы микропроцессорной системы это целая вечность, и за это вытесняющую многозадачность не любят…
Примечание: Есть тут также такой момент. Ядро Arduino Использует Timer0 в качестве системного. А теперь еще Timer2 под функции многозадачности отвели. Всего-то один таймер остаётся у пользователя. Непорядок. Я упоминал о том, что ядровые функции Arduino можно подменять в пользовательских библиотеках. Совершенно последовательное решение — дополнить обработчик прерывания переполнения счётчика Timer0, дополнив его функцию переключением контекста. И тем самым освободить Timer2 для пользовательских процессов. Но в рамках данной статьи это было бы избыточно…
Теперь задача практически решена.
Дело за малым. Написать все еще не определенную функцию copyContext(0x040A), разобраться с оператором goto и изготовить демонстрационную программу.
Но cначала полный листинг файла main.cpp:
#include <Arduino.h>
#include "MirmPS.h"
ISR(TIMER2_OVF_vect,ISR_NAKED)
{
saveContext(); // Сохраняем контекст.
if ((SPH*0x100+SPL)<0x420) // Очень глупый способ
// вычисления активного потока.
{
copyStackPointer(SPstore[1]);
loadStackPointer(SPstore[0]);
} // Сохраняем один SP
else
{ // И загружаем другой.
copyStackPointer(SPstore[0]);
loadStackPointer(SPstore[1]);
}
loadContext(); //Загружаем новый контекст.
asm("reti"); //Возврат из прерывания.
}
volatile void programm1 (void);
volatile void programm2 (void);
volatile SPstore_t SPstore[2]; // Здесь храняться указатели стека
// сохраненных потоков.
volatile int Taskcount=0; // Это счетчик выходов из ветвителя.
void branching(void)__attribute__((always_inline));
void branching_2 (void)__attribute__((naked,noinline));
void branching(void)
{ setStackPointer(0x04,0xFF); // установка SP в RAMEND
branching_2(); // точка вызова процедуры
// копирования.
//В эту точку возвращаются новые потоки.
//векторы выхода потоков из ветвителя:
if (Taskcount==0) {Taskcount++;goto *programm1;}
if (Taskcount==1) {Taskcount++;goto *programm2;}
}
void branching_2 (void)
{ saveContext(); //Сохраняем
SPstore[1].i=copyContext(0x040A); //Копируем
loadContext(); //Загружаем
//т.к. функция naked, нужно явно объявить возврат
asm("ret"); //Возвращаемся.
}
void loop1(void);
void loop2(void); //Функции реализованы в скетче.
void setup(void);
int main(void) //Точка входа программы.
{
init(); //Настройка ядра Ардуино. В основном таймеры.
cli(); //init() разрешает прерывания. но
//нам они пока не нужны. Запретим.
branching();//Ветвитель потоков.
return 0; //Сюда программа не попадёт.
}
volatile void programm1(void){ //А это два наших потока.
setup(); sei(); //Первый поток вызывает также cодержит
for (;;) {loop1(); //функцию setup.И разрешает прерывания.
}
} //За их вызов ответственна
volatile void programm2 (void){
for (;;) {loop2();} //функция branching()
}
Остался маленький штришок.
7. Часть седьмая, препроцессорно-ассемблерная.
Компилятор gcc — далеко не самая удобная вещь. В частности, когда дело касается ассемблерных вставок. Вы помните, сколько \n\t пришлось написать. Когда речь идет о передаче параметров в ассемблерную вставку и возврате значения, все становится еще муторнее (сюды читать)… Не то, чтобы неподъёмно, но не интересно.
Для написания фунции int copyContext(int) мы воспользуемся другим способом ассемблеро вставления, а именно подключением функций на языке ассемблера (читать сюды).
Создадим в нашей пользовательской библиотеке файлы MirmPS_assemf.h и Mirm_as.S.
Заголовочный файл «MirmPS_assemf.h», если помните, мы уже подключили в файле MirmPS.h.
MirmPS_assemf.h будет содержать заголовки, необходимые для того, чтобы функция copyContext, описанная в файле Mirm_as.S могла быть распознана препроцессором, линковщиком и компилятором.
Обратите внимание, на расширение Mirm_as.S. По соглашениям, принятым для среды Win никакой разницы между расширениями .S и .s не существует. Но дело в том, что .S — это не расширение, это окончание и ноги у него растут откуда-то со стороны линукса. Компилятор gcc в среде Arduino, настроен так, что файлы .s будут проигнорированы. Поэтому правильный вариант заглавный, Mirm_as.S.
Код файла MirmPS_assemf.h практически полностью состоит из директив препроцессора:
#ifndef _Mirm_Assembler_ //Защита от
#define _Mirm_Assembler_ //двойного подключения
//Общие определения
#ifdef __ASSEMBLER__
//Определения для ассемблера
.equ UDR0, 0xc6 // Эти определения в программе
.equ UCSR0A, 0xc0 // не используются. Приведены,
.equ TXC0, 6 // как пример.
#endif //#ifdef __ASSEMBLER__
#ifndef __ASSEMBLER__
//Определения не для ассемблера.
#ifdef __cplusplus
extern "C"{ //extern "C" декларирует, что
//передача параметров
//в функцию и возвращение результата
//должны вестись по соглашениям
//языка Си, а не C++.
#endif //#ifdef __cplusplus
int volatile copyContext(int)__attribute__((naked));
// copyContext:
// Определена, как naked. В данном случае это не обязательно.
// Определена, как volatile. На всякий случай.
// принимает и возвращает int по соглашениям языка Си.
#ifdef __cplusplus
} // extern "C"
#endif //#ifdef __cplusplus
#endif //#if not def __ASSEMBLER__
#endif //#ifndef _Mirm_Assembler_Это стандартное описание. Так все делают. Комментировать тут можно многое, но лучше поискать в интернетах. В интернетах все подробно и доходчиво.
Единственное, что нас по настоящему интересует, так это конструкция
extern "C"{
......
} Чтобы ее понять, надо знать, что разные языки программирования при передаче параметров и извлечении результата используют разные способы. Класификатор extern «C» говорит компилятору, передавать в функцию параметры надо как в языке «С» и также возвращать её результат. Называется это — порядок связывания языка «C». Важно понимать, что больше ни на что extern «C» не влияет. Писать функцию при этом можно на любом языке. И такое описание используют для связи с Ассемблером или же Фортраном.
Как же выглядит порядок связывания языка «C»? Для AVR данные будут передаваться в регистрах, с R25 (первый) по R8 (При этом очередной параметр всегда начинается в регистре с четным номером.). То, что не влезает, хитрым образом передается в стеке. Наш int будет лежать в R25:R24. И возвращенный результат, кстати, забираться будет оттуда же. Старший байт будет в R25. Младший в R24.
Теперь сама функция. она хранится в Mirm_as.S:
#include "MirmPS_assemf.h"
.global copyContext ; Объявление о том, что на точку
; copyContext будут ссылаться извне
copyContext: ;метка входа в функцию.
mov r30,r24 ;перемещаем полученное значение
mov r31,r25 ;в регистровую пару Z
ldi r29,0x05 ;устанавливаем в регистровую пару
ldi r28,0x00 ;Y адрес 0x0500
ldi r18,35 ;Нам надо отщелкать 35 байтов
;в r18 будет счетчик.
adiw r30,1 ;Инкрементация регистровой пары Z
;нужна по соображениям хитрой
;адресной математики
;С инициализацией закончили.
copyContext_1: ;Точка входа рабочего цикла
LD r19,-Y ;Декрементировать Y, после чего
;ЗАГРУЗИТЬ В регистр r19
;содержимое ИЗ ячейки на которую Y
;ссылается
ST -Z,r19 ;Декрементировать Z, после чего
;ЗАПИСАТЬ ИЗ регистра r19
;содержимое В ячейку на которую Z
;ссылается
dec r18 ;Декрементировать счетчик.
brne copyContext_1 ;Если r18 не равно нулю
;вернуться к точке copyContext_1
; иначе
sbiw r30,1 ;Декрементация регистровой пары Z
;нужна по соображениям хитрой
;адресной математики
mov r24,r30 ;Записываем назад в R25:R24
mov r25,r31 ;Тот адрес на котором мы остановились
ret ;Директива возврата из функции Как работает эта функция? Копирование осуществляется с помощью механизма косвенной адресации, реализованной в AVR. Этот механизм позволяет регистрам обращаться к ячейке памяти по ее адресу. При этом адрес храниться в одной из регистровых пар X,Y,Z. Это специальные регистровые пары, предназначенные для работы с механизмом косвенной адресации. X это R27:R26. Y это R29:R28. Z это R31:R30.
В Y кладем те адреса, откуда будем копировать. В Z те адреса, куда.
Есть хитрый момент. При косвенном чтении регистровую пару можно автоматически инкрементировать и декрементировать. Но почему-то инкрементация проходит как пост, а декрементация как пред. То есть, значение сперва декрементируется, а уже потом косвенно считывается. А пользуемся мы именно декрементацией.
Поэтому регистр Y ручками устанавливаем не 0x04FF, а в 0×0500 (дабы считать 0x04FF), и к регистру Z также предварительно прибавляем единичку.
Конструкция
dec r18
brne copyContext_1 Это счетчик цикла.
dec r18 Декрементирует r18.
brne copyContext_1 интересуется, возвращала ли предыдущая операция нулевой флаг (флаги — это биты регистра состояния SREG. Один из них устанавливается при нулевом исходе арифметических операций, таких как dec). Если флаг не установлен, то осуществляет переход назад на начало цикла. Если установлен, то прыжок на copyContext_1 игноририруется и программа покидает цикл.
Далее декрементируем адрес, лежащий в Z. Нужно это потому, что сейчас в Z лежит адрес последнего байта стека. А указатель должен ссылаться на байт ниже последнего байта, чтобы стек правильно читался. Таким образом, мы вычисляем точку, на которую должен ссылаться указатель стека.
Наконец возвращаем значение в R25:R24 (напоминаю про соглашение связывания языка Си.) и возвращаемся из функции.
Обращаю ваше внимание на то, что в заголовочном файле наша функция определена, как naked. Это предполагает, что пользователь сам позаботится о сохранении содержимого регистров к моменту возврата из функции. Мы же ничего подобного не делаем.
Вообще-то это грубая ошибка. Спасает то, что в нашей программе сразу за функцией copyContext() будет вызываться макрос loadContext(), загружающей сохраненный контекст. Поэтому увидеть печальных последствий мы не успеем. Но если столь вольно обращаться с регистрами, можно вполне прийти к логическому коллапсу программы…
Файлы MirmPS_assemf.h и Mirm_as.S готовы.
Всё… Библиотека написана.
Осталось написать тестовый скетч.
Но прежде немного отвлечеммся и поговорим про оператор goto.
8. Часть восьмая, в которой… Магия…
Функция
void branching(void)
{ setStackPointer(0x04,0xFF);
branching_2();
if (Taskcount==0) {Taskcount++;goto *programm1;}
if (Taskcount==1) {Taskcount++;goto *programm2;}
}
использует оператор goto в форме goto *(func). Не то, чтобы programm1 было обязательно вызывать через goto, но здесь это уместно.
Оператор goto — это самый многострадальный оператор языка Си… В чем его только не обвиняет.
И в том, что из-за него программы не читабельны. И в том, что из-за него компилятор не может эфективно проводить оптимизацию. В том, что он не укладывается в парадигму структурного программирования. В том, что его использование может привести к нарушению логической целостности программы. Последнее, кстати — абсолютная правда я это даже продемонстрирую.
Оператор goto это страшилка. Это то чем матёрые преподаватели пугают бедных студентов. Это как дети и спички. И не надо, мол, лазать там, где не надо лазать.
Но есть вещи пострашнее goto… Например ассемблерные вставки. Те самые, которые мы столь активно используем.
Тут получается какая-то несуразность. Если программист юзает ассемблер — он крут. Если оператор goto — он нуб. Интересно.
goto — это оператор безусловного перехода. Его операндом являются или метка или адрес функции. По сути, и то и другое транслируется адресом в программной памяти. Разница небольшая.
С точки зрения ассемблера goto может выглядеть как соответствующе оформленный переход на основе дирректив jmp или rjmp, или ijmp.
От ВЫЗОВОВ call,icall,rcall (на основе которых строятся функции) ПЕРЕХОДЫ jmp, rjmp, ijmp отличаются тем, что вызовы возвращают точку вызова в стек, а переходы не возвращают. В этом вся разница.
То есть переход
goto *programm1;отличается от вызова
programm1();, тем, что из вызова можно вернуться, а из перехода нет.
Это с точки зрения функциональности. Следует добавить, что компилятор автоматически оформляет вызов какими-то вещами, направленными на сохранение контекста. Переход, что логично, не оформляется.
А что-бы вы получше поняли, чем так опасен оператор goto я приведу пример.
Рассмотрим скетч Ардуино (ту замечательную библиотеку, что мы написали не подключаем. Сейчас она не нужна).
Вот код
void setup(void)
{goto *k;
while(1){};//цикл-ловушка, призванный подвесить программу по выходу из k.
}
void loop(void)
{digitalWrite(13,1);}
void k (void)
{
digitalWrite(13,1);delay(200);digitalWrite(13,0);delay(200);
}Как вы думаете, что произойдет?.. Если бы на месте goto *k; был бы вызов k() ответ был бы очевиден. Программа мигнет диодом и уснет на строке while(1){}, так никогда и не попадя в тело функции loop.
А если goto *k;
Правильный ответ — loop будет вызван. И светодиод, мигнув загорится на постоянной основе.
Механизм работы такой. Ядро Ардуино вызывает функцию
setup()Которая тут же выполняет переход
goto *k;Функция
void k (void)
{digitalWrite(13,1);delay(200);digitalWrite(13,0);delay(200);}Мигает светодиодом и… ВНИМАНИЕ… осуществляет возврат из функции.
«Куда?»,- воскликните вы. Ведь функция k() никогда не вызывалась и в стеке не содержится обратного адреса. Но что-то в стеке есть?
В стеке лежит адрес возврата из последней вызванной функции… функции setup()…
Круто, да?.. А после функции setup(), как известно выполняется функция loop().
Вот такая магия.
Так что же… Получается, что мы вернулись из функции setup() по возврату функции k(). А теперь представьте, что функция k() определена как int возвращает какое-то значение. Кому она чего вернет? Функции setup, которая void? Интересно, не так ли…
А давайте наоборот…
Усложним пример:
int a;
void setup() {
Serial.begin(9600);
a=func_int();
Serial.println(a);
}
void loop()
{}
void func_void ()
{}
int func_int () {
goto *func_void;
return(222);}
Что мы увидим по Serial интерфейсу?
Как вы, наверное, поняли, я подменил возврат из функции func_int(), который возвращает int возвратом из функции func_void(), которая не возвращает ничего.
Но…
a=func_int();Переменная «a» думает, что ей возвращают число int… И ищет его в тех регистрах, куда оно должно прийти.
Так что же мы увидим по Serial интерфейсу? Правильный ответ такой: «Всё, что угодно».
Заглянув в Serial, мы можем увидеть электронных человечков, следы информационного шторма, комнату, где малыш компилятор хранит свои игрушки… Может даже ответ на Главный вопрос жизни, Вселенной и всего всего такого.
Лично я увидел «152»…
Ну не магия ли? А магия может быть как вредной, так и полезной. goto — это остро отточенный меч. Им можно сокрушать врагов. С его помощью можно защищать друзей. А можно и зарезаться… Случайно.
Если дать меч в руки невежды, он много не навоюет. Он лишь покалечит себя и своих товарищей. Только понимая законы работы микроконтроллера, чувствуя и предсказывая действия союзника компилятора, можно полностью отдавшись чувству момента гордо написать goto и единым взмахом разрубить Гордиев Узел логической связности. Ибо величайшая структура — это отсутствие всякой структуры.
8. Часть восьмая, в которой программа запускается.
Повествование подходит к концу.
У нас есть библиотека, в которой лежат 4-ре файла.
И сейчас мы напишем скетч, который проиллюстрирует ее работу.
Стандартный скетч Ардуино состоит из функций
void setup() {
}
void loop() {
}Но мы функцию main переписали, а потому теперь основа скетча выглядит так:
#include <MirmPS.h>
void setup() {
}
void loop1() {
}
void loop2() {
}Можете проверить, компилятор ругаться не должен. Что мы будем запускать?
Простейший вариант, проверяющий правильность многопоточной работы.
#include <MirmPS.h>
void setup()
{ Serial.begin(9600);
TIMSK2=1;}
void loop2()
{digitalWrite(13,1);delay(500);digitalWrite(13,0);delay(500);}
void loop1()
{Serial.println("HelloWorld");delay(2000);}Видите. И светодиод мигает. И HelloWorld отписывается. Обратите внимания, что функции delay() повели себя неожиданно в том плане, что многопоточность совершенно не мешает им корректно отрабатываться. Эта приятная неожиданность объясняется тем, что в среде Arduino delay реализован на системном таймере, а не на пустом цикле.
Что до команды
TIMSK2=1;, то эта строка включает в работу переключатель контекста, разрешая соответствующее прерывание.
Но это маленькая демонстрация.
А теперь о настоящей двупоточной программе.
Мне понравился осциллограф, представленный в статье.
Он бесподобен. Он состоит из небольшого скетча Ардуино и большого скетча для Processing.
Скетч для процессинга вот (не забудьте вставить в скетч номер своего COM-порта.
Для этого надо модифицировать соответствующим образом строчку
port = new Serial(this,«COM1», 38400); // Serial.list()[0]):
import processing.serial.*;
Serial port; // Create object from Serial class
int valA;
int valB;
int valC;
int valD;
int valE;
int valF;
// this should have been some kind of 2-diminsional array, I guess, but it works.
int[] valuesA;
int[] valuesB;
int[] valuesC;
int[] valuesD;
int[] valuesE;
int[] valuesF;
PFont fontA;
PFont fontB;
void setup()
{
// make sure you have these fonts made for Processing. Use Tools...Create Font.
// "fontA" is a 48 pt font of some sort. It's what we use to show the "now" value.
fontA = loadFont("CourierNewPSMT-48.vlw");
// "fontB" is a 14 pt font of some sort. It's what we use to show the min and max values.
fontB = loadFont("CourierNewPSMT-14.vlw");
// I wouldn't change the size if I were you. There are some functions that don't use
// the actual sizes to figure out where to put things. Sorry about that.
size(550, 600);
// Open the port that the board is connected to and use the same speed
// anything faster than 38.4k seems faster than the ADC on the Arduino can keep up with.
// So, if you want it to be smooth, keep it at or below 38400. 28800 doesn't work at all,
// I do not know why. If you turn on smooth() you need to drop the rate to 19.2k or lower.
// You will probably have to adjust Serial.list()[1] to get your serial port.
port = new Serial(this,"COM1", 38400); // Serial.list()[0]
// These are 6 arrays for the 6 analog input channels.
// I'm sure it could have just as well been a 2d array, but I'm not that familiar
// with Processing yet and this was the easy way out.
valuesA = new int[width-150];
valuesB = new int[width-150];
valuesC = new int[width-150];
valuesD = new int[width-150];
valuesE = new int[width-150];
valuesF = new int[width-150];
// the -150 gives us room on the side for our text values.
// this turns on anti-aliasing. max bps is about 19.2k.
// uncomment out the next line to turn it on. Personally, I think it's better left off.
//smooth();
}
int getY(int val)
{
// I added -40 to this line to keep the lines from overlapping, to
// keep the values within their gray boxes.
return (int)(val / 1023.0f * (height-40)) - 1;
}
void draw()
{
String decoder = "";
while (port.available() >= 3)
{
// read serial until we get to an "A".
decoder = port.readStringUntil(65);
}
// sanity check. make sure the string we got from the Arduino has all the values inside.
if ((decoder.indexOf("B")>=1) & (decoder.indexOf("C")>=1) &
(decoder.indexOf("D")>=1) & (decoder.indexOf("E")>=1) &
(decoder.indexOf("F")>=1))
{
// decoder string doesn't contain an A at the beginning. it's at the end.
valA=int(decoder.substring(0,decoder.indexOf("B")));
//println("A" + str(valA));
valB=int(decoder.substring(decoder.indexOf("B")+1,decoder.indexOf("C")));
//println("B" + str(valB));
valC=int(decoder.substring(decoder.indexOf("C")+1,decoder.indexOf("D")));
//println("C" + str(valC));
valD=int(decoder.substring(decoder.indexOf("D")+1,decoder.indexOf("E")));
//println("D" + str(valD));
valE=int(decoder.substring(decoder.indexOf("E")+1,decoder.indexOf("F")));
//println("E" + str(valE));
valF=int(decoder.substring(decoder.indexOf("F")+1,decoder.indexOf("A")));
//println("F" + str(valF));
}
//shift the new values into the array, move everything else over by one
for (int i=0; i<width-151; i++)
{
valuesA[i] = valuesA[i+1];
valuesB[i] = valuesB[i+1];
valuesC[i] = valuesC[i+1];
valuesD[i] = valuesD[i+1];
valuesE[i] = valuesE[i+1];
valuesF[i] = valuesF[i+1];
}
// -151 because the array is 151 less than the width. remember we
// saved room on the side of the screen for the actual text values.
valuesA[width-151] = valA;
valuesB[width-151] = valB;
valuesC[width-151] = valC;
valuesD[width-151] = valD;
valuesE[width-151] = valE;
valuesF[width-151] = valF;
background(0);
textFont(fontA);
// I'm sure these c/should have been determined using height math, but I don't have the time really.
// Draw out the now values with the big font.
text(valA + 1, (width-140), 108-5);
text(valB + 1, (width-140), 206-5);
text(valC + 1, (width-140), 304-5);
text(valD + 1, (width-140), 402-5);
text(valE + 1, (width-140), 500-5);
text(valF + 1, (width-140), 598-5);
textFont(fontB);
// Draw out the min and max values with the small font.
// the h value (30,128,266,etc) is a function of height,
// but I didn't bother to actually do the math.
// I guess it's (98*n)+30 where n is 0,1,2,3,4,5, but I don't know
// exactly how height (600) relates to 98... ((h/6)-2??)
drawdata("0", width-90, 30, valuesA);
drawdata("1", width-90, 128, valuesB);
drawdata("2", width-90, 226, valuesC);
drawdata("3", width-90, 324, valuesD);
drawdata("4", width-90, 422, valuesE);
drawdata("5", width-90, 520, valuesF);
for (int x=150; x<width-1; x++)
{
// next line adjusts the color of the stroke depending on the x value. (fades out the end of the line)
check(x,255,0,0);
// next line draws the line needed to get this value in the array to the next value in the array.
// the offsets (6+ in the next line) were used to get the values where I wanted them without
// having to actually do real spacial math. There's a hack in getY that offsets a little, too.
line((width)-x,
6+((height/6)*0)+((height-1-getY(valuesA[x-150]))/6), (width)-1-x,
6+((height/6)*0)+((height-1-getY(valuesA[x-149]))/6));
check(x,0,255,0);
line((width)-x,
4+((height/6)*1)+((height-1-getY(valuesB[x-150]))/6), (width)-1-x,
4+((height/6)*1)+((height-1-getY(valuesB[x-149]))/6));
check(x,0,0,255);
line((width)-x,
2+((height/6)*2)+((height-1-getY(valuesC[x-150]))/6), (width)-1-x,
2+((height/6)*2)+((height-1-getY(valuesC[x-149]))/6));
check(x,255,255,0);
line((width)-x,
0+((height/6)*3)+((height-1-getY(valuesD[x-150]))/6), (width)-1-x,
0+((height/6)*3)+((height-1-getY(valuesD[x-149]))/6));
check(x,0,255,255);
line((width)-x,
-2+((height/6)*4)+((height-1-getY(valuesE[x-150]))/6), (width)-1-x,
-2+((height/6)*4)+((height-1-getY(valuesE[x-149]))/6));
check(x,255,0,255);
line((width)-x,
-4+((height/6)*5)+((height-1-getY(valuesF[x-150]))/6), (width)-1-x,
-4+((height/6)*5)+((height-1-getY(valuesF[x-149]))/6));
}
// draw the boxes in gray.
stroke(170,170,170);
// these 5 lines divide the 6 inputs
line(0,108,width-1,108);
line(0,206,width-1,206);
line(0,304,width-1,304);
line(0,402,width-1,402);
line(0,500,width-1,500);
// these four lines make up the outer box
line( 0, 0, width-1, 0); // along the top
line(width-1, 0, width-1, height-1); // down the right
line(width-1, height-1, 0, height-1); // along the bottom
line( 0, height-1, 0, 0); // up the left
}
void drawdata(String pin, int w, int h, int[] values)
{
text("pin: " + pin, w, h);
text("min: " + str(min(values) + 1), w, h + 14);
text("max: " + str(max(values) + 1), w, h + 28);
}
void check(int xx, int rr, int gg, int bb)
{
// floating point operations in Processing are expensive.
// only do the math for the float (fading out effect) if
// we have to. You can change 170 to 160 if you want it to
// fade faster, but be sure to change the other 170 to 160
// and the 20 to 10.
// (20 is the difference between 170 and 150)
if (xx<=170)
{
float kick = (parseFloat(170-xx)/20)*255;
// invert kick so the brighter parts are on the left side instead of the right.
stroke(rr,gg,bb,255-kick);
}
else
{
stroke(rr,gg,bb);
}
}
(не забудьте вставить в скетч номер своего COM-порта.
Для этого надо модифицировать соответствующим образом строчку
port = new Serial(this,«COM1», 38400); // Serial.list()[0])
Всё. Дело за малым, запустить его на Processing-е.
А что до скетча Ардуино, то он вот:
//
// Oscilloscope
// http://accrochages.drone.ws/en/node/90
//
#define ANALOGA_IN 0
#define ANALOGB_IN 1
#define ANALOGC_IN 2
#define ANALOGD_IN 3
#define ANALOGE_IN 4
#define ANALOGF_IN 5
int counter = 0;
void setup()
{
Serial.begin(38400);
}
void loop()
{
int val[5];
val[0] = analogRead(ANALOGA_IN);
val[1] = analogRead(ANALOGB_IN);
val[2] = analogRead(ANALOGC_IN);
val[3] = analogRead(ANALOGD_IN);
val[4] = analogRead(ANALOGE_IN);
val[5] = analogRead(ANALOGF_IN);
Serial.print( "A" );
Serial.print( val[0] );
Serial.print( "B" );
Serial.print( val[1] );
Serial.print( "C" );
Serial.print( val[2] );
Serial.print( "D" );
Serial.print( val[3] );
Serial.print( "E" );
Serial.print( val[4] );
Serial.print( "F" );
Serial.print( val[5] );
}Маленький, но удаленький…
Чуть чуть изменим его.
Подключим #include MirmPS.h.
В функции setup() добавим строку TIMSK2=1;
Функцию loop переименуем в loop1, а в конец файла добавим еще чуть чуть кода — наш второй процесс.
Вот таким образом:
#include <MirmPS.h>
//
// Oscilloscope
// http://accrochages.drone.ws/en/node/90
//
#define ANALOGA_IN 0
#define ANALOGB_IN 1
#define ANALOGC_IN 2
#define ANALOGD_IN 3
#define ANALOGE_IN 4
#define ANALOGF_IN 5
int counter = 0;
void setup()
{
Serial.begin(38400);
TIMSK2=1;
}
void loop1()
{
int val[5];
val[0] = analogRead(ANALOGA_IN);
val[1] = analogRead(ANALOGB_IN);
val[2] = analogRead(ANALOGC_IN);
val[3] = analogRead(ANALOGD_IN);
val[4] = analogRead(ANALOGE_IN);
val[5] = analogRead(ANALOGF_IN);
Serial.print( "A" );
Serial.print( val[0] );
Serial.print( "B" );
Serial.print( val[1] );
Serial.print( "C" );
Serial.print( val[2] );
Serial.print( "D" );
Serial.print( val[3] );
Serial.print( "E" );
Serial.print( val[4] );
Serial.print( "F" );
Serial.print( val[5] );
}
float j=0;float i=0;
void loop2()
{analogWrite(5,(sin(j)+1)*128);
j=j+PI/720/6; if (j>2*PI) j=0;
analogWrite(6,i);
i=i+0.05; if (i>255) i=0;
}Как видите, второй процесс чего-то там аналогово вырисовывает.
Я думаю, вы поняли логику. Я собираются одним Ардуино и рисовать аналоговый сигнал во втором потоке и одновременно его считывать в первом потоке.
Однако непосредственно считать не получится, ибо analogWrite, как вы знаете — не аналоговый сигнал, а ШИМ сигнал… Если мы подадим его на осциллограф, то в лучшем случае увидим скачки разной кучности. В худшем — не увидим ничего. Для того, чтобы ШИМ сигнал превратить в настоящий аналоговый сигнал, его надо отфильтровать. В сумме это уже будем цифро-аналоговый преобразователь.
Схема.
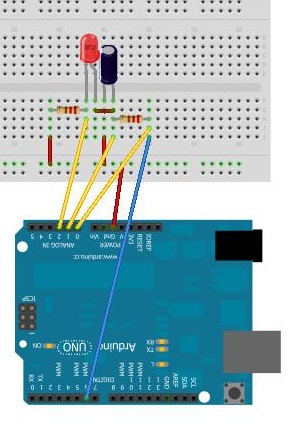
… Это половина схемы. Вывод номер 5 и еще 3 аналоговых входа подключаются анлогично… Конденсатор у меня на 470 микроФарад резисторы по 100 Ом.
Вот результат работы всей системы:
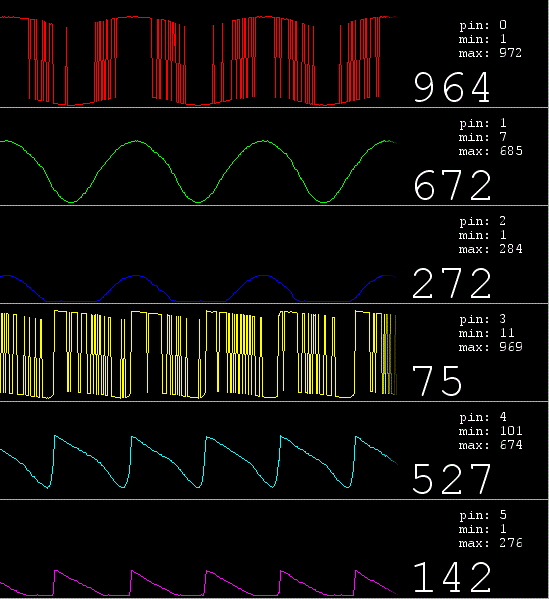
Что мы тут видим?.. Ну во первых, что наш ЦАП — дерьмо. Как только светодиод открывается, он тут же проседает.
Ну, и конечно, что многопоточность работает. Это не может не радовать.
Тоже самое вживую:
Собственно, основное преимущество многопоточности было продемонстрировано. Две не связанные программы без лишних раздумий запустились на одной платформе.
9. Часть девятая. Последняя.
Прежде чем отпустить ваше внимание (если оно еще сохраняется)…
Я должен отметить еще две-три вещи:
Функции ядра Ардуино рассчитаны на работу в режиме постоянных прерываний от системного таймера.
Это значит, что они не критичны к остановам и не разрушаются в многопоточном режиме. Это очень удобно. Если же есть какие-то сомнения, функцию всегда можно сделать атомарной, выполнив перед ней макрос cli(), а после нее макрос sei(). В этом случае на время работы такой функции прерывания будут запрещены.
Если есть переменные, с которыми работают сразу оба процесса, их следует описывать как volatile, а обращения к ним делать атомарными.
О динамическом распределении памяти. Я писал второй стек в кучу. А куча распределяется при динамическом распределении… Если подключить распределение, будет коллапс. Что делать, если нужно динамическое распределение? Это очевидно. Динамически распределить место под стек и писать туда, не забывая, что стек пишется сверху вниз.
И, наконец, третье. Мы сделали два потока. Но никто не мешал сделать три или четыре. Можно повесить переключение контекста на любое прерывание. Никто не мешает создавать потоки динамически по ходу выполнения программы. Не запрещает вводить приоритеты…
И вообще… Мы вольны делать все, что захотим. И это хорошо.
Спасибо.
Баг репорт №1: Чтобы можно было вызывать функции, работающие на основе прерываний (например Wire.endTransmision) из тела функции setup(), необходимо в функции programm1 поменять местами вызовы функции setup() и макроса sei(). Глобальное разрешение прерываний должно идти раньше вызова функции setup().